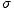|
zufällig ist und nicht den Ergebnissen in der Literatur
entspricht.7
Neu erhobene Daten, mit denen das System jedoch noch nicht trainiert wurde, zeigen
weniger einheitliche Tendenzen. In den gegebenen Versuchsdaten sind klare Trends
festzustellen, die die Notwendigkeit der Berücksichtigung verschiedener Faktoren und die
Problematik einer geeigneten Gewichtung verdeutlichen. Bei 7 von 8 Versuchen ist die
Gruppenlänge monoton steigend mit dem Tempo. Der eine abweichende Fall läßt sich als
die Wahrnehmung von Vierergruppen bestehend aus zwei Zweiergruppen plausibel
erklären. Dieser Trend läßt sich durch die Bevorzugung bestimmter Gruppendauern
erklären, die eine Erhöhung der Gruppenlänge bei erhöhtem Tempo bewirkt. Die
Annahme einer bevorzugten Dauer allein ist aber nicht ausreichend, denn andererseits
werden die Gruppenlängen 2 und 4 deutlich bevorzugt (Häufigkeit der Längen 2: 48, 3:
7, 4: 41). Die Gruppenlänge hat also ebenfalls einen Einfluß. Es müssen die
verschiedenen Merkmale Gruppendauer und Gruppenlänge geeignet abgebildet und
gegeneinander abgewogen werden, was sich in den Gewichten darstellen muß. Ein
geeignetes Einstellen der Gewichte von Hand ist bereits bei diesen relativ einfachen
Aufgaben kaum noch zu realisieren.
Das ISSM wurde mit diesen Beispielen mit einem Teil des Netzes aus Kapitel 9 trainiert, der nur die relevanten Neuronen und Verbindungen bzw. Prädikate und Regeln enthält. Dabei traten auf der Trainingsmenge Fehlinterpretationen bei 18 von 96 Beispielen (18,8 %) auf. Dies ist ein sehr guter Wert, denn die Daten enthalten widersprüchliche Beispiele. Dieser Wert liegt nur um ein Beispiel über der minimal möglichen Anzahl von 17 Fehlinterpretationen, d.h. nur 1,3% der maximal möglichen richtigen Interpretationen wurden nicht erreicht.8
Auf der Testmenge betrug der Fehler 10 von 40 (25%), das sind 2 mehr als die minimal
mögliche Anzahl (6,7%). Das System kann sich also den Daten sehr gut anpassen und
liefert auch gute Ergebnisse auf Testdaten. Dabei ergaben sich die Gewichte aus Tabelle
11.3.
Die Gewichte entsprechen deutlich den Tendenzen, die auch aus der Anschauung der Daten ersichtlich wurden: Die Gruppenlänge 3 erhält eine schlechtere Bewertung als 2 und 4. Die bevorzugten Gruppendauern liegen zwischen 0,7 und 1,2 sec, wobei die Länge ein deutlich höheres Gewicht hat als die Dauer (0,1 zu 0,001). Zum Vergleich wurde ein lineares Netz mit der gleichen Trainingsmenge trainiert. Die Ergebnisse sind deutlich schlechter: 34 von 96 (35% / 21,5%) auf der Trainingsmenge und 19 von 40 (47% / 30%) auf der Testmenge. Bereits bei einem solchen begrenzten Problem und einer relativ kleinen Menge von Beispielen ist das lineare Modell offenbar nicht mehr ausreichend. Segmentierung nicht isochroner SequenzenAls Grundlage dienen die gleichmäßigen Sequenzen aus dem letzten Abschnitt. Zu
den Einsatzzeiten und Intensitäten wurde Gaußsches Rauschen addiert mit
|