ein globales Minimum darstellt. Man kann zwar bei schlechter
Systemperformance mit anderen Startwerten erneut trainieren, um evtl.
ein besseres lokales Minimum zu finden, ein allgemeines Verfahren zur
Bestimmung des globalen Minimums gibt es aber nicht.
Ein Gradient 0 kann auch eine Sattelfläche oder ein Plateau auf der
Fehlerfläche bedeuten. Das Training bleibt hier stehen, obwohl kein Minimum
erreicht wurde.
Das Training kann zwischen verschiedenen Punkten oszillieren, ohne den
Fehler zu minimieren.
Das Training ist oft langsam und wenig wirkungsvoll, insbesondere wenn das
Netz viele Schichten hat (Faustregel: mehr als drei), weil der Gradient in den
von der Ausgabe entfernten Schichten sehr klein wird.
Die Wahl der Lernrate ist kritisch. Wird sie zu klein gewählt, ist der
Algorithmus nicht effizient und bleibt leicht in einem schlechten lokalen
Minimum stecken. Wählt man sie zu groß, so steigt die Gefahr, gute Minima
zu verlassen oder eine Oszillation zu erhalten.
Es wurde eine Reihe von Methoden entwickelt, die diesen Problemen entgegenwirken
sollen. Eine verbreitete Technik zur Beschleunigung des Trainings ist das Momentum,
das eine Art Trägheit der Gewichtsänderung darstellt. In jedem Schritt wird zur aktuell
berechneten Änderung ein Anteil der letzten Änderung addiert, der dafür sorgt, daß
flache Bereiche der Fehlerfläche schneller verlassen werden.
Eine weitere Verbesserung bieten Verfahren, die statt der Verwendunge einer
globalen Lernrate die Größe der Gewichtsänderung für jedes Gewicht getrennt
anpassen. Ein Beispiel für einen solchen Algorithmus ist der in dieser Arbeit
verwendete Resilient Backpropagation Algorithmus (RPROP) von Riedmiller und
Braun.13
Bei diesem Verfahren hängt die Gewichtsänderung nur vom Vorzeichen des Gradienten
bzgl. des betrachteten Gewichts, d.h. der partiellen Ableitung des Fehlers nach
dem betrachteten Gewicht, im aktuellen und vorangegangenen Zyklus ab. Die
Lernrate
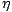 ij(t)
ij(t) für ein Gewicht
wij zum Zeitpunkt
t wird, abhängig von der
partiellen Ableitung zum Zeitpunkt
t,
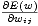 (t)
(t), für jedes Gewicht getrennt
berechnet:
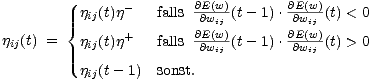 | (5.11) |
Sind die Vorzeichen des aktuellen und des vorigen Gradienten gleich, wird die
Lernrate vergrößert. Sind die Vorzeichen verschieden, hat man für dieses
Gewicht ein lokales Minimum überschritten und verkleinert die Schrittweite.
Man benötigt statt einer Lernrate drei Konstanten: Einen Startwert (0),
einen Vergrößerungsfaktor