verwendete
Fehlerfunktion ist die quadratische Summe über die Trainingsmuster aus
P:
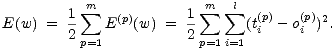 | (5.6) |
Dabei ist oi der tatsächliche Ausgabewert des Neurons xi, Der Faktor 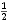 erleichtert das
Rechnen mit den Ableitungen und hat sonst keine Auswirkungen.
erleichtert das
Rechnen mit den Ableitungen und hat sonst keine Auswirkungen.
Das Ziel des Verfahrens ist, die Gewichte so zu verändern, daß die Abweichung der
tatsächlichen Aktivierung der Ausgabeneuronen oi vom gewünschten Zielwert ti
möglichst klein wird, indem man versucht, die Fehlerfunktion zu minimieren. Dazu wird
vorausgesetzt, daß alle verwendeten Funktionen der Netzeingabe, Aktivierung und
Fehlerberechnung differenzierbar sind, um ein Gradientenabstiegsverfahren zu
verwenden. Der Gradient 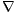 f einer mehrdimensionalen Funktion f bezeichnet
den Steigungsvektor in einem Punkt. Der Gradientenabstieg besteht darin, die
Argumente in dem Gradienten entgegengesetzter Richtung zu verändern, um
den Funktionswert zu minimieren. Bei Backpropagation betrachtet man den
Fehlerwert als Funktion der Gewichte und verändert die Gewichte, um den Fehler zu
verringern:
f einer mehrdimensionalen Funktion f bezeichnet
den Steigungsvektor in einem Punkt. Der Gradientenabstieg besteht darin, die
Argumente in dem Gradienten entgegengesetzter Richtung zu verändern, um
den Funktionswert zu minimieren. Bei Backpropagation betrachtet man den
Fehlerwert als Funktion der Gewichte und verändert die Gewichte, um den Fehler zu
verringern:
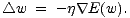 | (5.7) |
Für ein einzelnes Gewicht ergibt sich daraus
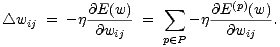 | (5.8) |
Die Konstante 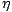 bezeichnet wieder die Lernrate und bestimmt den Betrag der
Gewichtsänderung. Man setzt dabei 0 < < 1 voraus. Für ein Netz mit gewichteter
Summe als net und flog als Aktivierungsfunktion lassen sich die Werte rekursiv
berechnen:
bezeichnet wieder die Lernrate und bestimmt den Betrag der
Gewichtsänderung. Man setzt dabei 0 < < 1 voraus. Für ein Netz mit gewichteter
Summe als net und flog als Aktivierungsfunktion lassen sich die Werte rekursiv
berechnen:
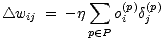 | (5.9) |
mit
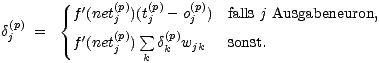 | (5.10) |
Die Fehlerfunktion bildet den Raum der Parameter auf den Fehler ab. Hat man nur zwei
Parameter, so erhält man eine Fläche im  3. Der Gradientenabstieg bedeutet
anschaulich, daß man von einem Anfangspunkt ausgehend der Neigung der Fehlerfläche
abwärts folgt, bis die Neigung 0 ist. Dann geht man davon aus, daß man an einem
Tiefpunkt angelangt ist. Ein solcher Tiefpunkt stellt dann eine Parameterwahl dar, für
die der Fehler lokal minimal wird.
3. Der Gradientenabstieg bedeutet
anschaulich, daß man von einem Anfangspunkt ausgehend der Neigung der Fehlerfläche
abwärts folgt, bis die Neigung 0 ist. Dann geht man davon aus, daß man an einem
Tiefpunkt angelangt ist. Ein solcher Tiefpunkt stellt dann eine Parameterwahl dar, für
die der Fehler lokal minimal wird.
Die Anwendung von Backpropagation wirft einige Probleme auf, die hier kurz
dargestellt werden sollen:
- Man hat im allgemeinen keine Gewißheit, daß das gefundene Minimum
auch