zeigten in ihrer Untersuchung
von 1969,
9
daß Perceptrons die XOR-Funktion nicht berechnen können, d.h. eine elementare
logische Funktion läßt sich mit einem Perceptron nicht modellieren. Minsky und Papert
zeigten zwar auch, daß eine Verknüpfung von Perceptrons das Problem mit geeigneten
Gewichten lösen konnte, aber es gab keinen Lernalgorithmus, der diese Gewichte
automatisch aus Beispielen hätte berechnen können. Daraufhin ließ das Interesse an
künstlichen neuronalen Netzen zunächst deutlich nach.
Erst 1986 wurde durch die Veröffentlichung des Error-Backpropagation-Algorithmus von
Rummelhart, Hinton und Williams die Forschung im Bereich neuronaler Netze wieder
belebt.10
Es stellte sich später heraus, daß das Verfahren parallel dazu schon von anderen Forschern
entwickelt und veröffentlicht worden war, bereits 1974 war es von Paul Werbos beschrieben
worden.
11
Das Backpropagation-Verfahren verallgemeinert das Perceptron-Lernen auf
mehrschichtige Netze und läßt sich mathematisch elegant als Gradientenabstiegsverfahren
herleiten.
Man kann ein neuronales Netz allgemein so definieren:
Definition 5.1.2 Ein neuronales Netz ist ein Tupel (N,E,A,G), wobei
N = {x1,...,xn} die Menge der Neuronen, E 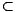 N die Menge der
Eingabe-Neuronen, A N die Menge der Ausgabe-Neuronen und G die Menge der
gewichteten Kanten bezeichnet. Zu jedem Neuron gehören jeweils ein Schwellenwert
N die Menge der
Eingabe-Neuronen, A N die Menge der Ausgabe-Neuronen und G die Menge der
gewichteten Kanten bezeichnet. Zu jedem Neuron gehören jeweils ein Schwellenwert
 i und eine Aktivierungsfunktion fi. Eine gewichtete, gerichtete Kante ist ein
Tupel (ki,kj,wij), wobei ki
i und eine Aktivierungsfunktion fi. Eine gewichtete, gerichtete Kante ist ein
Tupel (ki,kj,wij), wobei ki  N \ A kein Ausgabe-Neuron und kj N \ E kein
Eingabe-Neuron sein darf und das Gewicht wij eine reelle Zahl ist.
N \ A kein Ausgabe-Neuron und kj N \ E kein
Eingabe-Neuron sein darf und das Gewicht wij eine reelle Zahl ist.
Enthält ein Netz keine Zyklen, so findet der Signalfluß nur in eine Richtung von der
Eingabeschicht zur Ausgabeschicht statt. Eine solche azyklische Architektur wird als
vorwärtsgerichtetes Netz (engl. feed-forward) bezeichnet. Neuronale Netze werden häufig
in Schichten organisiert. D.h. das Netz besteht aus Teilmengen Ni,i = 1,...,l, mit
N1 = E und Nl = A, innerhalb derer es keine Verbindungen gibt und zwischen denen es
Verbindungen nur zur nächsten Schicht gibt:
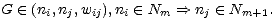 | (5.3) |
Diese Schichten sind üblicherweise voll vernetzt, d.h. jedes Neuron hat eine Verbindung
zu jedem Neuron der nächsten Schicht:
 | (5.4) |
Die Schichten, die nicht aus Eingabe- oder Ausgabeneuronen bestehen, heißen versteckte
Schichten. Das Multi-Layer-Perceptron von Rummelhart, Hinton und Williams stellt sich
dann als ein Spezialfall dar:
Definition 5.1.3 Ein vorwärtsgerichtetes neuronales Netz,
das aus einer Eingabeschicht, einer oder mehreren versteckten Schichten und einer
Ausgabeschicht besteht, heißt Multi-Layer-Perceptron (MLP).