sich für kleine
Operanden nicht besser durch eine lineare Funktion approximieren läßt als für größere.
Wahrscheinlichkeitstheoretisch kann man den Trainingsprozeß mit Weight-Decay als Übergang
von einer
a priori Wahrscheinlichkeitsverteilung zu einer
a posteriori Wahrscheinlichkeit
interpretieren.
6
Kleine Gewichte in einem fuzzy-logischen Programm sind aber als
a priori-Modell nicht
plausibel, weil die Merkmale und Regeln gerade so konstruiert sind, daß man bei ihnen a
priori einen erheblichen Einfluß annimmt. Eine mögliche Alternative wäre hier, die
Regeln vorab aufgrund inhaltlicher Überlegungen mit Wahrheitswerten zu belegen.
Ausgehend von diesen Werten könnte man beim Training das Weight Decay
nicht bezüglich des absoluten Betrags, sondern bezüglich der Differenz von
aktuellem Wert und Vorbelegung durchführen, was bisher aber noch nicht erprobt
wurde.
12.4.2. Relatives Training
Braun berichtet, daß die Wahl eines möglichst großen  -Abstandes die
Generalisierung verbessert, solange noch alle Beispiele richtig bewertet
werden.7
-Abstandes die
Generalisierung verbessert, solange noch alle Beispiele richtig bewertet
werden.7
Dies ist vermutlich darauf zurückzuführen, daß bei großem
das Verhalten des Netzes
stärker durch die Daten bestimmt wird. Bei kleinen
beeinflußt die Initialisierung der
Gewichte die Bewertung, was bei Beispielen aus der Testmenge zu Fehlentscheidungen
führen kann.
Der -Wert für das relative Training muß geeignet gewählt werden, um sowohl
Trainingserfolg als auch gute Generalisierung zu erreichen. Dabei kann man zwei Fälle
unterscheiden:
- Die Trainingsmenge kann vom Netz vollständig gelernt werden, alle Beispiele
werden korrekt bewertet.
- Die Trainingsmenge kann nicht vollständig gelernt werden. Es bleiben
Eingaben, für die das System andere Interpretationen als die vorgegebene
auswählt.
Im ersten Fall geht eine Überlegung zur Anpassung der Größe von dahin, den Wert
so zu wählen, daß eine vollständige Ordnung auf den absoluten Beispielen möglich wird,
in der jedes Paar von Beispielen einen Unterschied der Bewertung von mindestens hat.
Dazu darf nicht größer als 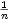 für eine Menge mit n Trainingsbeispielen sein. Ein
Wert von
für eine Menge mit n Trainingsbeispielen sein. Ein
Wert von 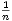 hat sich in der Praxis allerdings als noch zu groß herausgestellt.
Um den Wert geeignet zu verkleinern, kann man versuchen, wie bei Braun
vorgeschlagen, mit binärer Suche einen -Wert zu ermitteln, der möglichst groß
ist, aber noch zuläßt, daß alle Beispiele gelernt werden können. Dies wurde in
RhythmScan implementiert. Für kleine Beispielmengen zeigt sich auch eine
leichte Verbesserung der Generalisierung gegenüber konstantem . Bereits für
Trainingsmengen mit ca. 20 Beispielen ist allerdings ein vollständiges Lernen durch das
Netz meist nicht mehr möglich. Da es im allgemeinen keine Möglichkeit gibt,
dies im vorhinein festzustellen, ist es normalerweise nicht sinnvoll, den -Wert
zu verkleinern, bis alle Beispiele gelernt werden, da der Wert dann 0 wird.
Daher
hat sich in der Praxis allerdings als noch zu groß herausgestellt.
Um den Wert geeignet zu verkleinern, kann man versuchen, wie bei Braun
vorgeschlagen, mit binärer Suche einen -Wert zu ermitteln, der möglichst groß
ist, aber noch zuläßt, daß alle Beispiele gelernt werden können. Dies wurde in
RhythmScan implementiert. Für kleine Beispielmengen zeigt sich auch eine
leichte Verbesserung der Generalisierung gegenüber konstantem . Bereits für
Trainingsmengen mit ca. 20 Beispielen ist allerdings ein vollständiges Lernen durch das
Netz meist nicht mehr möglich. Da es im allgemeinen keine Möglichkeit gibt,
dies im vorhinein festzustellen, ist es normalerweise nicht sinnvoll, den -Wert
zu verkleinern, bis alle Beispiele gelernt werden, da der Wert dann 0 wird.
Daher