Man setzt voraus, daß
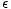
normalverteilt mit Mittel
0 ist. Für unabhängige Datenpunkte
wird die Wahrscheinlichkeit der Datenpunkte, die Likelihood
L, bestimmt durch:
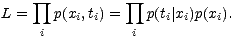 | (5.16) |
Wenn man für die Netzausgabe y(x) die Wahrscheinlichkeit der Daten (x,t) unter der
Verteilung y(x) + betrachtet, kann man zeigen, daß die Minimierung des
Quadratsummenfehlers 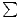 (y - t)2 gerade die Maximierung der Wahrscheinlichkeit der
Daten bezüglich y(x) + bedeutet, weswegen dieser Ansatz auch Maximum-Likelihood
genannt wird. Weiterhin kann man zeigen, daß sich für große Datenmengen die
Netzausgabe dem Durchschnitt von t unter der Bedingung x annähert:
(y - t)2 gerade die Maximierung der Wahrscheinlichkeit der
Daten bezüglich y(x) + bedeutet, weswegen dieser Ansatz auch Maximum-Likelihood
genannt wird. Weiterhin kann man zeigen, daß sich für große Datenmengen die
Netzausgabe dem Durchschnitt von t unter der Bedingung x annähert:
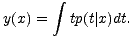 | (5.17) |
Für Klassifikationsprobleme ist eine andere Fehlerfunktion günstig. Sei t eine
Ausgabe, die 1 wird, wenn x einer Klasse C1 angehört, und 0, wenn x einer
Klasse C2 angehört. Dann läßt sich die bedingte Dichte von t folgendermaßen
schreiben:
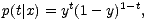 | (5.18) |
und die Likelihood L
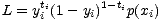 | (5.19) |
läßt sich durch die Verwendung der folgenden Fehlerfunktion maximieren:
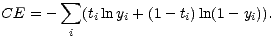 | (5.20) |
Diese Fehlerfunktion heißt Cross-Entropie, und ihre Minimierung liefert wieder einen
Maximum-Likelihood-Schätzwert für p und damit die bedingte Wahrscheinlichkeit
p(C1|x).
Der Bayessche Ansatz betrachtet statt der Wahrscheinlichkeit der Daten für ein
Modell die Wahrscheinlichkeitsverteilung der Gewichte unter der Bedingung der Daten
nach dem Satz von Bayes:
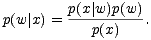 | (5.21) |
Der Lernvorgang stellt dann den Übergang von einer a priori Wahrscheinlichkeit zu einer
a posteriori Wahrscheinlichkeit der Gewichte dar. Ziel des Lernvorgangs ist nicht
nur, die wahrscheinlichsten Gewichtswerte unter Verwendung einer a priori
Wahrscheinlichkeit und der Trainingsbeispiele zu bestimmen, sondern man erhält durch
die Verteilung auch Aussagen über die Zuverlässigkeit der ermittelten Werte. Lernen mit
Weight-Decay entspricht dabei einer Maximum-Likelihood-Schätzung der Gewichte mit
der Normalverteilung um den Mittelwert 0 als a priori Wahrscheinlichkeit.