10.2.3. Klassifikation oder Regression
Bei relativem und iterativem Training von Bewertungen sind zwei Auffassungen der
Lernaufgabe möglich. Man kann versuchen, den Betrag der Fehlbewertung zu
minimieren, dann handelt es sich um eine Regressionsaufgabe, oder die Zahl der
Fehlbewertungen, dann geht es um ein Klassifikationsproblem.
Für ein Regressionsproblem ist die quadratische Summe der Abweichungen ein
geeignetes Fehlermaß. Man hält damit den Fehlerbetrag für jedes Beispiel klein, da die
Ableitung des Gesamtfehlers nach der Fehlbewertung eines Beispiels proportional zur
Fehlbewertung ist. Es wird hier implizit vorausgesetzt, daß große Aktivierungen des
Komparatorneurons auch großen Fehlern der relativen Bewertung entsprechen. Dies ist
aber nicht notwendigerweise der Fall. Beim Training mit relativen Bewertungen werden
keine Informationen darüber verwendet, wieviel die EI besser bewertet werden sollte als
die SI. Im Fall des iterativen Trainings steht diese Information auch nicht zur
Verfügung, da der Experte keinen Vergleich vornimmt sondern nur die EI vorgibt.
Daher wird als Zielwert des Komparatorneurons 0 angenommen, obwohl der
Zielwert der relativen Bewertung t := t(xr) - t(xl) eigentlich negativ ist. Die
Netzeingabe netKn des Komparatorneurons für ein Trainingsbeispiel n stellt
also nur einen Anteil der relativen Fehlbewertung für ein Interpretationspaar
aus EI und SI dar, nämlich netKn = y(xrn) - y(xln). netKn ist bei einem
Fehlurteil des Systems positiv, der Zielwert tn dagegen negativ. Da der Zielwert der
Bewertung t für verschiedene Trainingsbeispiele unterschiedlich groß sein kann, ist es
möglich, daß für den gesamten Bewertungsfehler en := netKn - tn bei zwei
relativen Beispielen n und m gilt en < em bei netKn > netKm. Das bedeutet, daß
kleine Fehler einen stärkeren Einfluß auf das Training haben können als große
Fehler.
Eine Alternative ist daher, die Aufgabe als Klassifikationsproblem zu interpretieren.
Man klassifiziert die Beispiele, indem man für jedes Paar (xl,xr) feststellt, ob die rechte
Interpretation, die EI, um  besser bewertet wird als die linke. Alle iterativ erzeugten
relativen Beispiele sind in der Klasse der Beispiele mit besserer linker Eingabe. Das
Komparatorneuron ist ein Indikator für Klassen mit besserer rechter Eingabe und sollte
daher bei Bewertung der Beispiele immer 0 ergeben. Ziel dieses Ansatzes ist, die
Zahl der falsch klassifizierten Paare zu minimieren. Dazu wird eine sigmoide
Aktivierungsfunktion des Komparatorneurons verwendet, so daß sich für Beispiele mit
korrekter relativer Bewertung eine Ausgabe nahe 0 und für Beispiele mit falscher
Bewertung eine Ausgabe nahe 1 ergibt. Das dazu geeignete Fehlermaß ist die
Cross-Entropie1
besser bewertet wird als die linke. Alle iterativ erzeugten
relativen Beispiele sind in der Klasse der Beispiele mit besserer linker Eingabe. Das
Komparatorneuron ist ein Indikator für Klassen mit besserer rechter Eingabe und sollte
daher bei Bewertung der Beispiele immer 0 ergeben. Ziel dieses Ansatzes ist, die
Zahl der falsch klassifizierten Paare zu minimieren. Dazu wird eine sigmoide
Aktivierungsfunktion des Komparatorneurons verwendet, so daß sich für Beispiele mit
korrekter relativer Bewertung eine Ausgabe nahe 0 und für Beispiele mit falscher
Bewertung eine Ausgabe nahe 1 ergibt. Das dazu geeignete Fehlermaß ist die
Cross-Entropie1
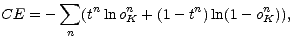 | (10.11) |
wobei tn den Zielwert und oKn die Ausgabe für das n-te Trainingsbeispiel bezeichnet. Da
im ISSM für alle Beispiele t = 0 gilt, reduziert sich das CE-Maß in unserem