|
Während die ersten Takthälften autonom generiert werden, erfolgt die Generierung der Stimmen in der zweiten Takthälfte abhängig vom Kontext nach folgendem Schema:
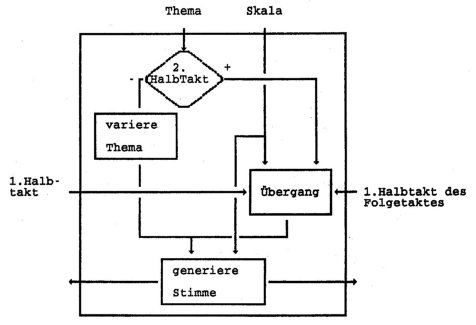
Abbildung 3
Für die Repräsentation des Themas wird eine tonart-unabhängige Notation benötigt, die von den Variationsmethoden transformiert und an die aktuelle Skala angepaßt werden kann:
[ [ [ [ [ [ [ [ |